
SQL 파싱과 최적화
SQL 특징 ⭕ 암기
- 구조적
- 집합적
- 선언적
- select * from s_emp
- 선언과 명령의 차이
- 선언적 : 어떤 데이터를 가져올지만 명시
- 명령적: 어떤 데이터(what)를 어떻게(how) 가져올지 명시
SQL 최적화 ⭕ 암기
SQL을 실행하기 전에 진행됨
- SQL 파싱
- SQL 파싱 트리 생성
- SQL 최적화
- 통계 정보 바탕으로 가장 효율적인 방법 선택
- 로우소스 생성
- 실행 경로를 실행 가능한 코드 or 프로시저로 변환
최적화 종류
- Rule Base 안씀
- Cost Base
- 통계기반
실행 계획
- 통계 정보로 만든 추정치임. 실제 수행시간과 차이 있음
- 트리 형태
JOIN
- for문 2개
- 테이블 2개 연결
옵티마이저 힌트
수동 명령
사용 상황
- 자동으로 만들어진 실행계획을 보고 성능이 잘 안나올 떄 수동 명령(힌트) 사용
표현 /* + 힌트내용 */ 주석안에 + 붙이기
특징
- 인덱스 힌트를 명시했는데, 어떤 인덱스를 사용할지 명시하지 않으면 옵티마이저가 결정
SQL 공유 및 재사용
세션과 프로세스가 라이브러리 캐시의 캐싱 SQL을 공유함.
세션
- sid 한개가 세션 1개 가리킴
프로세스
- OS 프로세스가 최소 1개의 DB 세션을 담당
-- 세션
-- sid가 하나의 세션 의미
select sid, username, status
from v$session;
-- 세션과 프로세스 매핑
-- 한 OS 프로세스에 여러 세션 매핑
SELECT s.sid, p.spid
FROM v$session s
JOIN v$process p ON s.paddr = p.addr;
--WHERE s.username = 'YOUR_USER';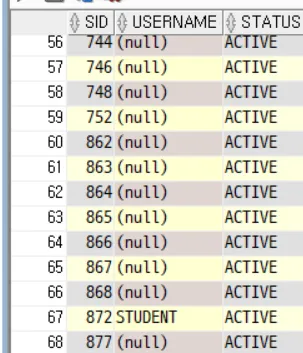

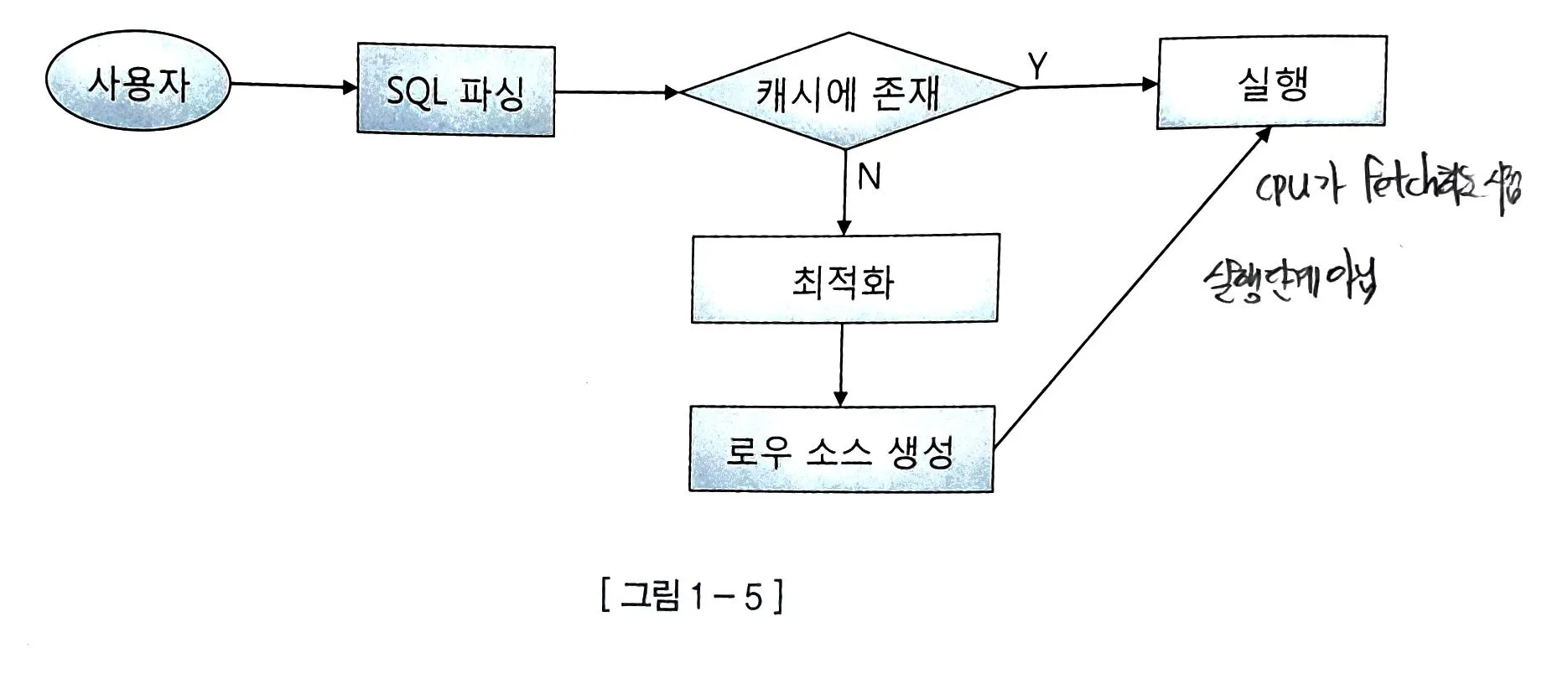
소프트 파싱 soft parsing
캐싱 SQL
- SQL을 캐시에서 찾아 바로 CPU가 실행 (fetch)
하드 파싱 hard parsing
파싱 직접
- 캐시에 SQL문이 없으면 SQL 최적화, 로우 소스 생성 후 CPU가 실행
메모리 종류 -2 ⭕암기
- SGA 공유 메모리 share [ Java ] cv
- PGA 개인 메모리. private [ Java ] iv
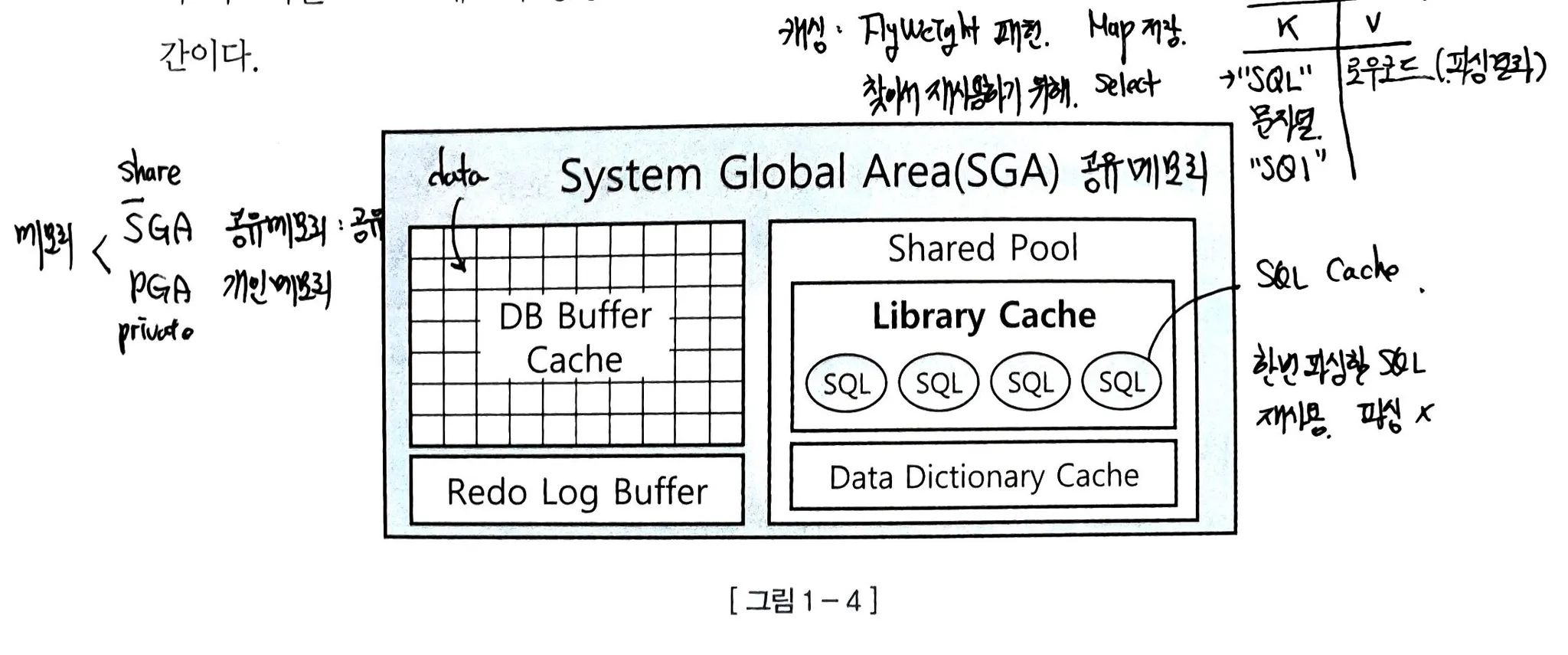
라이브러리 캐시에 SQL 옵티마이저를 통해 생성된 프로시저가 저장
캐시 저장 구조 Map ⭕ 중요
- Key : 문자열이 동일한 SQL
- 의미상 동일해도 문자열 다르면 Value 가 같은 Key가 여러 행이 Map에 저장됨.
- 문자열은 대소문자, 공백, 주석까지 같아야함
- Value : 해당 SQL의 로우 소스
parameter driven
SQL 문 텍스트는 그대로 유지하고, 값만 변수(parameter)로 분리해 작성하는 것
튜닝 🟢
- SQL 텍스트를 라이브러리 캐시에 한번만 하드 파싱하여 실행 계획을 세우고, 이후에 소프트 파싱으로 곧바로 실행
- 파싱 오버헤드 감소
PreparedStatement vs 일반 Statemnet 차이 ⭕ 면접
- 성능
- 보안 sql injection 방지
대답: SQL 캐시를 이용할 수 있어 성능 올라감
cf Statemnet + ‘ ‘
String sql = "SELECT * FROM student WHERE name = '" + name + "'"; -- 일반 Statemnt 문
String sql = "SELECT * FROM student WHERE name = ?"; -- PreparedStatement 바인드 변수 이용
Web 캐시 정책
- hit 수 낮은 것 (잘 안쓰는 것)
- 오래된 것
기준으로 eviction 밀려남
성능은 캐시가 결정함
데이터 저장 구조 및 I/O 메커니즘
SQL 이 느린 이유
- I/O 때문. 입출력 동안 CPU가 일을하지 않음. 잠
I/O 횟수 줄이는 법
- 불필요한 컬럼 읽지 않기
- ex.테이블 컬럼 크기 축소 - null 저장되어있거나 데이터가 없을 때
- 데이터 압축
데이터베이스 저장 구조⭕ 암기

테이블 스페이스
- 저장공간. 파일 n개로 구성
- 세그먼트 담는 컨테이너. (데이터)파일 여러개
세그먼트 segment
오브젝트 종류별로 저장함
한 컬럼이 매우 큰 크기를 가지면, 참조 (주소)만 컬럼에 저장하고, 실제 데이터를 가리키도록 함.
- BLOB 바이너리. ex.이미지파일
- CLOB 텍스트
논리적, 물리적 구조
논리적
- 합쳐진 상태
물리적
- 논리적으로는 세그먼트가 합쳐져있지만, 물리적으로 분리되어 있음.
- 물리적으로 분리되어 있으면 각각 나눠있어 I/O의 속도가 빠름.
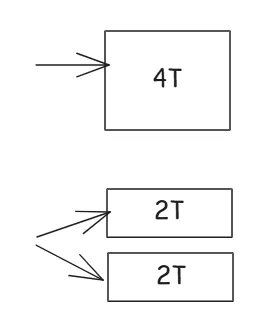
테이블 스페이스는 데이터 파일이 물리적으로 여러 개로 나눠 저장된 점이 I/O 속도를 높이기 위함이다.
- 논리적으로는 데이터가 4T(테라바이트) 크기인 데이터로 합쳐진 상태이지만, 물리적으로 2T씩 2개로 나눠 저장되어 있다면, 각각 동시에 나눠 읽으면 I/O 속도가 빠른 것과 같다.
익스텐트 extent
- 세그먼트의 공간은 익스텐트 단위로 확장
- 연속된 블록 집합
- 여러 익스텐트끼리 불연속적인 공간에 위치
블록 block
- I/O(데이터 읽고 쓰는) 최소 단위
- 로우로 구성
- 같은 익스텐트 내 여러 블록들은 연속적인 공간에 위치
로우 row
- SQL 문

Block 단위 I/O
테이블, 파일, 인덱스 모두 블록 단위로 입출력
빈 공간(row)가 많으면 I/O 횟수가 증가함. → 빈공간 채우기 필요
- I/O의 최소 단위는 블럭인데, 블럭 안의 row 한행을 읽기 위해 row가 포함된 블럭을 통째로 읽어야함.
- INSERT 중간에 row 넣기
- Append 맨뒤에 추가
읽는 방법 -2 ⭕ 암기
- 시퀀설 액세스 (= 순차)
- 정렬이 되든 안되는 있는 그대로 탐색
- 논리적 혹은 물리적 순서를 따름
- 랜덤 액세스
- 인덱스
- 한번에 하나의 블록 읽음.
- 논리적, 물리적인 순서 따르지 않음
Full Scan 전체 데이터 다 봄. Sequential. 대량 검색 유리
Random Scan 인덱스. 한번에 하나 읽음. 소량 검색 유리. 읽는데 오래 걸림.
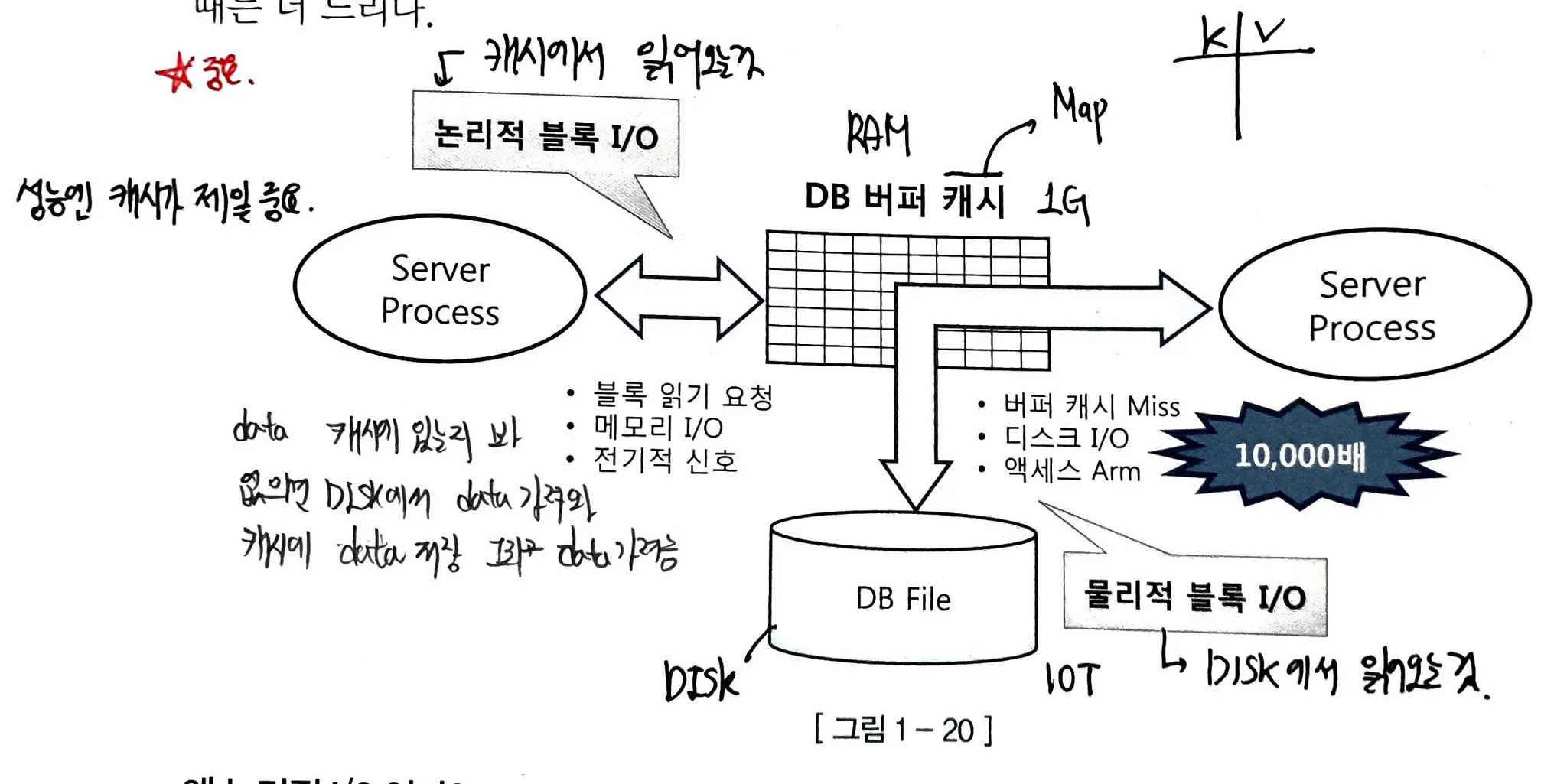
논리적 I/O
- RAM에 있는 캐시에서 데이터를 읽어옴
- SQL을 처리하는 과정에서 발생한 총 블록 I/O
물리적 I/O
- 디스크에서 데이터를 읽어오는 것.
- 데이터가 캐시에 없다면 디스크에서 데이터를 읽고, 캐시에 데이터 저장 후 데이터를 가져옴(읽음)
- 디스크에서 발생한 총 블록 I/O
Single Block I/O
캐시에서 찾지 못한 데이터를 읽을 때 한번에 1개의 Block만 읽어 메모리에 올리는 방식
Index Scan(블록 단위로 읽음), 랜덤 액세스, 소량 검색 ⭕ 암기
Multi Block I/O
한번에 Block 여러개를 메모리에 올리는 방식
Full Scan(테이블 전체 스캔), 시퀀설 액세스. 대량 검색 ⭕ 암기
Table Full Scan
테이블 전체를 스캔해서 읽는 방식
시퀀셜 액세스, MultiBlock I/O 방식으로 디스크 블록 읽음.
- 한 블록에 속한 모든 레코드(행) 한 번에 읽음,
- 캐시에서 못찾으면 한번의 I/O 콜(잠)을 통해 같은 익스텐트에 속한 인접한 수십 ~ 수백 개 블록을 한 꺼번에 가져옴.
Index Range Scan
인덱스를 이용해서 테이블을 읽는 방식
랜덤 액세스, SingleBlock I/O 방식으로 디스크 블록 읽음.
캐시의 탐색 (데이터 읽는) 원리
해싱 이용
- 해시 함수를 이용해 탐색
액세스 직렬화(접근 줄세우기)
- 두 개 이상의 프로세스가 동시에 접근하려고할 때 사용
- 읽고 있는데, 누가 고치면 안되기 때문. 데이터 불일치
- 래치1 latch vs 락 lock 차이점
Latch LOCK 대기 방식 큐 X
잠금 시도 실패 시 짧게 기다렸다가 재시도
큐 관리 없이 선착순으로 자원 획득큐 O
대기중인 세션이 정확한 순서대로 권한 얻고
대기 큐에서 빠져나옴오버헤드 낮음 높음 (큐 관리) 직렬화 대상 SGA 공유 메모리 자원 보호 테이블, 행, 인덱스, 트랜잭션 등
데이터베이스 객체
참고
<친절한 SQL 튜닝, 조시형>
'Database' 카테고리의 다른 글
| [Modeling] Ch03. 논리 모델링 (0) | 2025.05.18 |
|---|---|
| [Modeling] Ch02.개념 모델링 (0) | 2025.05.12 |
| [Modeling] Ch01. 데이터 모델링 이론 (0) | 2025.05.12 |
| [Database] Ch10.Dictionary (0) | 2025.05.11 |
| [Database] Ch11.DDL 데이터 정의어 (0) | 2025.05.11 |